ASP.NET上传一个文件夹
![]() 相关资料:
相关资料:![]() 解决方案,
解决方案,![]() 白皮书,
白皮书,![]() 产品介绍,
产品介绍,![]() 产品比较,
产品比较,![]() 开发文档,成功案例,基础组件,示例下载,控件包,控件升级,在线演示,在线文档,并发能力,上传速度,下载速度,
开发文档,成功案例,基础组件,示例下载,控件包,控件升级,在线演示,在线文档,并发能力,上传速度,下载速度,![]() Windows控件安装,
Windows控件安装,![]() macOS控件安装,
macOS控件安装,![]() Linux-deb控件安装,
Linux-deb控件安装,![]() Linux-rpm控件安装,安装引导,控件布署,控件升级,
Linux-rpm控件安装,安装引导,控件布署,控件升级,![]() IE9加载控件,
IE9加载控件,![]() IE8加载控件,
IE8加载控件,
![]() 示例下载:
示例下载:![]() asp.net-vs2013,
asp.net-vs2013,![]() asp.net-vs2010,
asp.net-vs2010,![]() jsp-eclipse,
jsp-eclipse,![]() jsp-springboot,
jsp-springboot,![]() jsp-myeclipse,
jsp-myeclipse,![]() php,
php,![]() vue-cil,
vue-cil,![]() WinForm(C#),
WinForm(C#),![]() C++(WTL)
C++(WTL)
![]() 教程:
教程:![]() WinForm(C#)测试,
WinForm(C#)测试,![]() WTL(C++)测试,
WTL(C++)测试,![]() 在vue.js中使用,
在vue.js中使用,![]() 在vue-cli中使用,
在vue-cli中使用,![]() eclipse导入up6
eclipse导入up6
![]() 视频教程:
视频教程:![]() windows控件安装,
windows控件安装,![]() mac控件安装,
mac控件安装,![]() linux-deb控件包安装,
linux-deb控件包安装,![]() linux-rpm控件包安装,
linux-rpm控件包安装,![]() php7测试,
php7测试,![]() php5测试,
php5测试,![]() vue-cli-测试,
vue-cli-测试,![]() asp.net-IIS Express测试,
asp.net-IIS Express测试,![]() asp.net-IIS测试,
asp.net-IIS测试,![]() asp.net-阿里云(oss)测试,
asp.net-阿里云(oss)测试,![]() asp.net-华为云(obs)测试,
asp.net-华为云(obs)测试,![]() jsp-springboot测试,
jsp-springboot测试,![]() ActiveX(x86)源码编译,
ActiveX(x86)源码编译,![]() ActiveX(x64)源码编译,
ActiveX(x64)源码编译,![]() Windows(npapi)源码编译,
Windows(npapi)源码编译,![]() macOS源码编译,
macOS源码编译,![]() Linux(x86_64)源码编译,
Linux(x86_64)源码编译,![]() Linux(arm)源码编译,
Linux(arm)源码编译,![]() Linux(mips-uos)源码编译,
Linux(mips-uos)源码编译,![]() Linux(mips-kylin-涉密环境)源码编译,sm4加密传输,压缩传输,
Linux(mips-kylin-涉密环境)源码编译,sm4加密传输,压缩传输,
![]() ASP.NET教程:
ASP.NET教程:![]() asp.net,IIS Express,IIS,IIS-Https,
asp.net,IIS Express,IIS,IIS-Https,![]() Oracle,minio,fastdfs,
Oracle,minio,fastdfs,![]() 阿里云对象存储(oss),
阿里云对象存储(oss),![]() 华为云对象存储(obs)
华为云对象存储(obs)
![]() jsp-eclipse教程:测试教程,oracle,
jsp-eclipse教程:测试教程,oracle,![]() mysql,
mysql,![]() SQL Server,minio,fastdfs,
SQL Server,minio,fastdfs,![]() 阿里云对象存储(oss),
阿里云对象存储(oss),![]() 华为云对象存储(obs),
华为云对象存储(obs),
![]() jsp-springboot教程:测试教程,minio,fastdfs,
jsp-springboot教程:测试教程,minio,fastdfs,![]() 阿里云对象存储(oss),
阿里云对象存储(oss),![]() 华为云对象存储(obs)
华为云对象存储(obs)
![]() jsp-myeclipse教程:
jsp-myeclipse教程:![]() mysql,oracle,
mysql,oracle,![]() SQL Server,fastdfs
SQL Server,fastdfs
![]() php教程:测试教程,minio,fastdfs,
php教程:测试教程,minio,fastdfs,![]() 阿里云对象存储(oss),
阿里云对象存储(oss),
![]() 二次开发:组件引用,自定义事件,自定义业务字段,自定义文件保存路径,授权码,加密存储,加密传输,使用Minio存储,使用FastDFS存储,
二次开发:组件引用,自定义事件,自定义业务字段,自定义文件保存路径,授权码,加密存储,加密传输,使用Minio存储,使用FastDFS存储,![]() 使用达梦数据库,数据表字段设计,监控fd_create流程,监控f_create流程,监控f_list.jsp流程
使用达梦数据库,数据表字段设计,监控fd_create流程,监控f_create流程,监控f_list.jsp流程
![]() 相关问题:WebSocket连接失败,md5计算完毕后卡住,域名未授权,网站安全系统拦截,
相关问题:WebSocket连接失败,md5计算完毕后卡住,域名未授权,网站安全系统拦截,
![]() 联系我们:
联系我们:![]() QQ:1269085759(技术),
QQ:1269085759(技术),![]() QQ:3040217208(售后),
QQ:3040217208(售后),![]() QQ:1085617561(商务),
QQ:1085617561(商务),![]() 微信:13235643658,
微信:13235643658,![]() 邮箱:1269085759@qq.com,
邮箱:1269085759@qq.com,![]() 1085617561@qq.com,
1085617561@qq.com,![]() qwl@ncmem.com,
qwl@ncmem.com,









产品交流群:
视频教程:https://www.bilibili.com/video/BV1Vs4y1b7yh/?vd_source=d1843c7f8c164416779b5188178bad8c
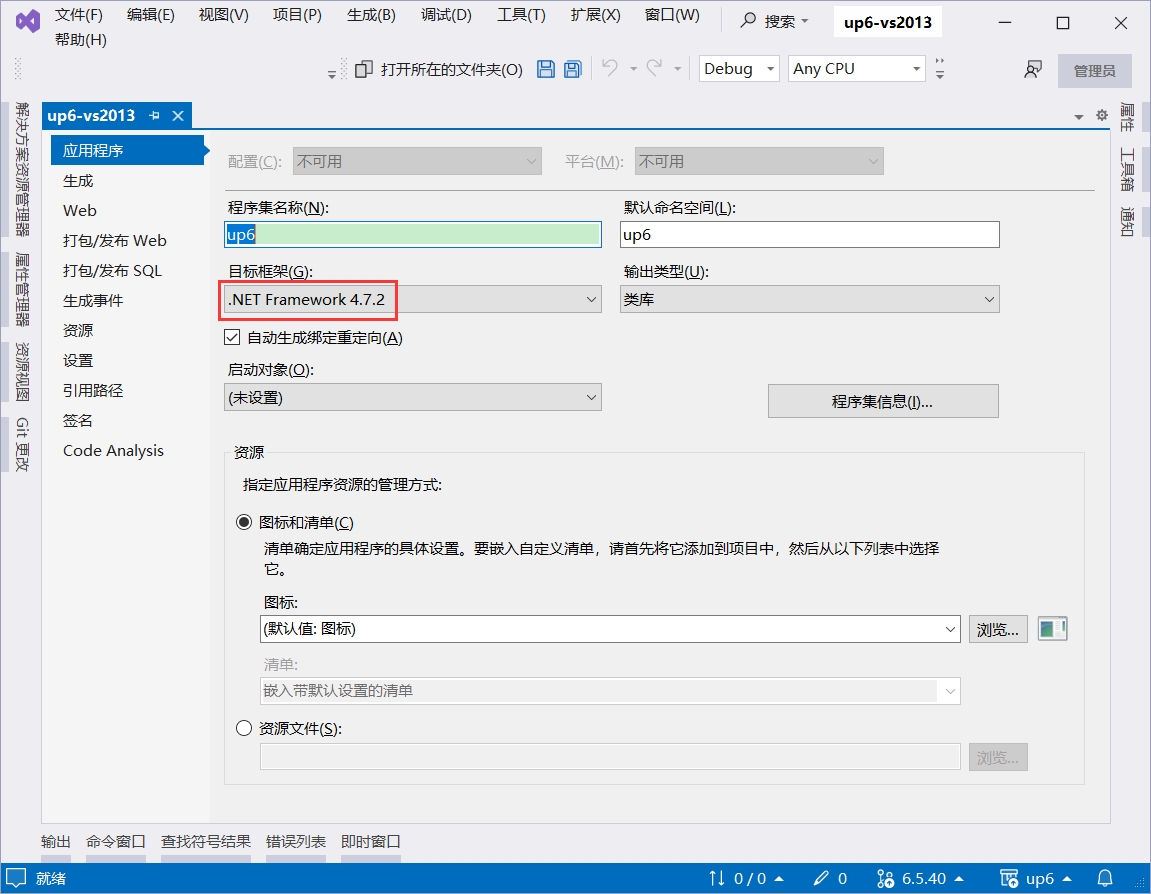
框架:.NET Framework 4.7.2
版本:6.5.41
示例:https://gitee.com/xproer/up6-asp-net/tree/6.5.41/

安装.NET Framework 4.7.2
https://dotnet.microsoft.com/en-us/download/dotnet-framework/net472
![]() 百度网盘:https://pan.baidu.com/s/13CGIHrRDSc1pPc-gR8miog?pwd=bnbl
百度网盘:https://pan.baidu.com/s/13CGIHrRDSc1pPc-gR8miog?pwd=bnbl
框架选择4.7.2
添加3rd引用

编译项目

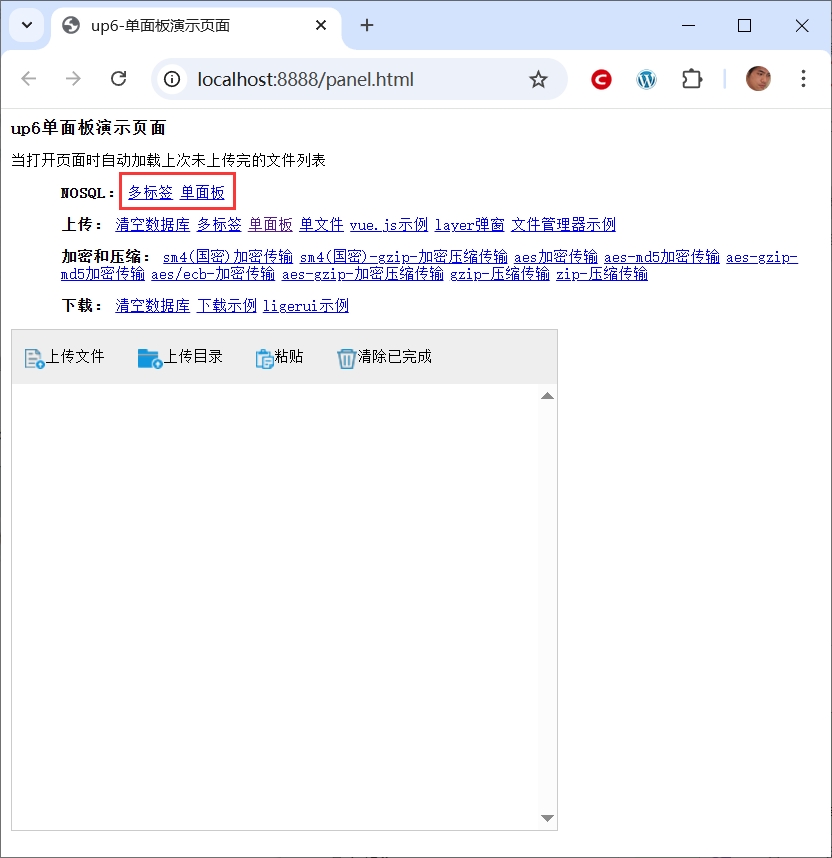
NOSQL
NOSQL无需任何配置可直接访问页面进行测试
SQL
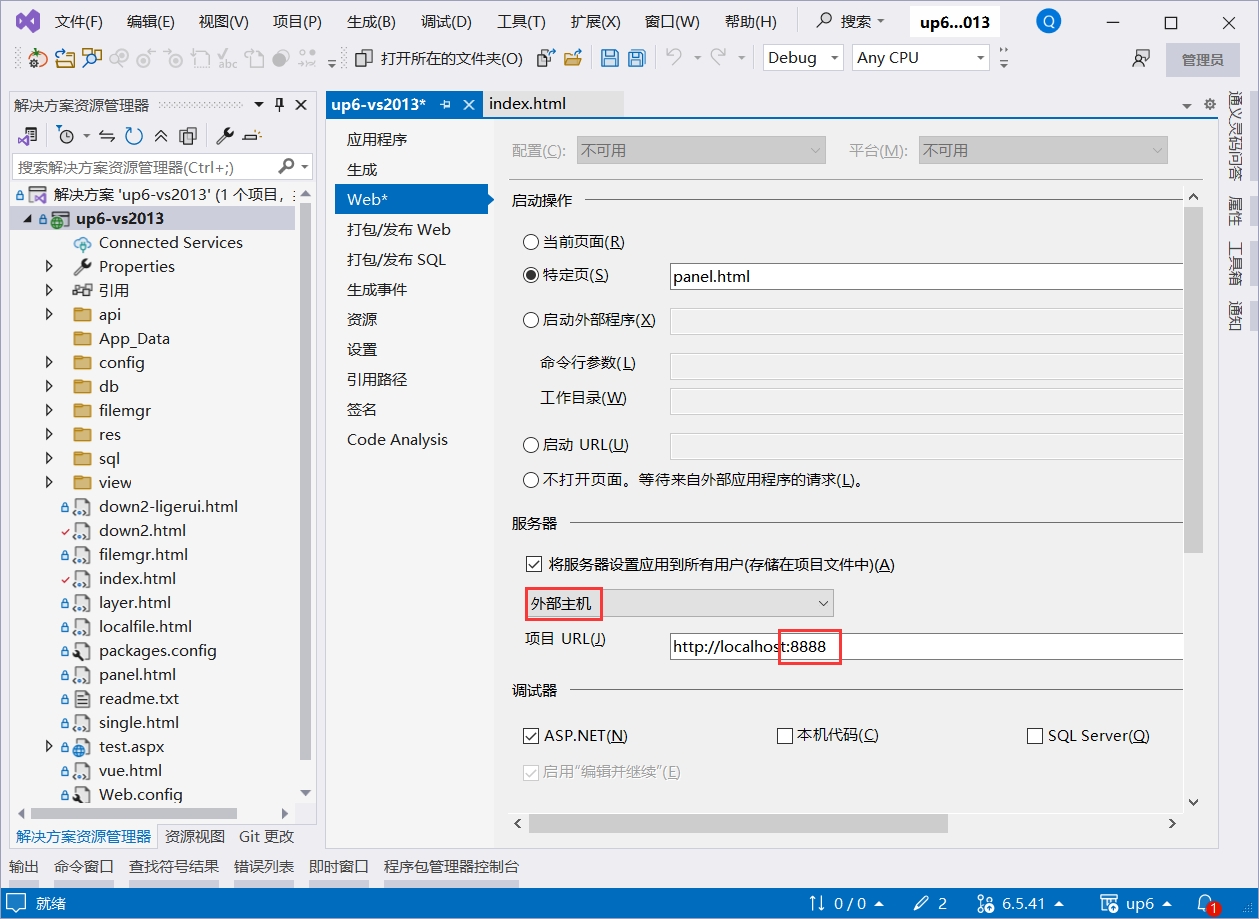
使用IIS
大文件上传测试推荐使用IIS以获取更高性能。
使用IIS Express
小文件上传测试可以使用IIS Express

创建数据库
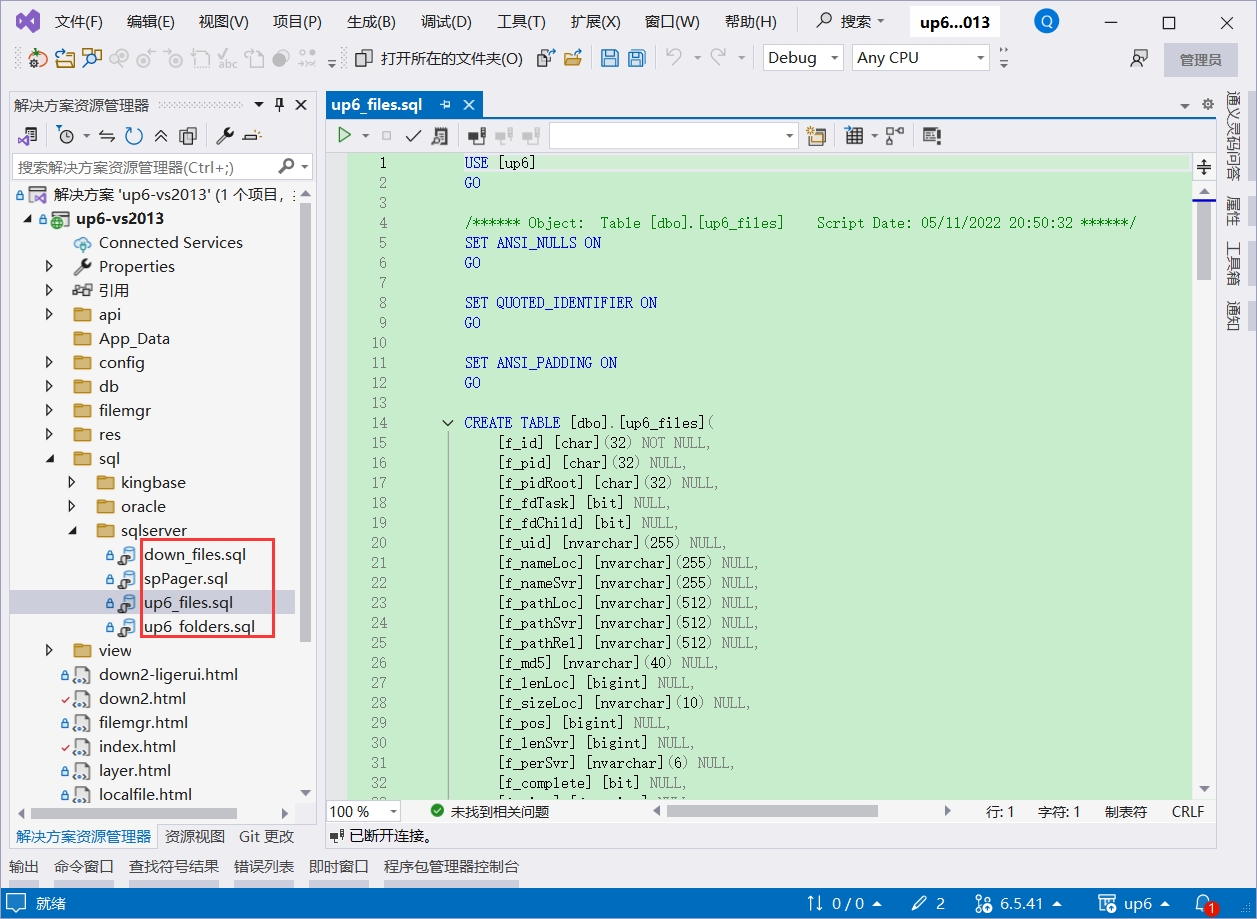
配置数据库连接信息
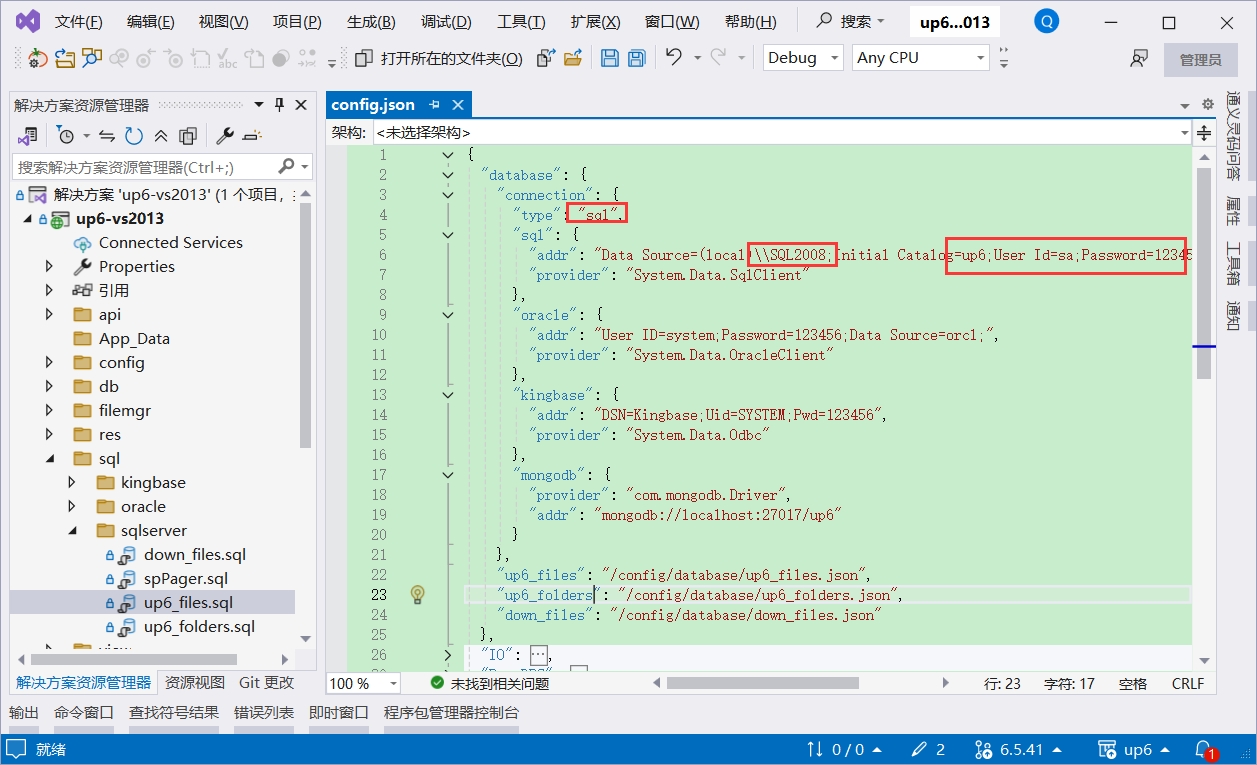
检查数据库配置
点击“清空数据库”链接,测试数据库配置是否正确
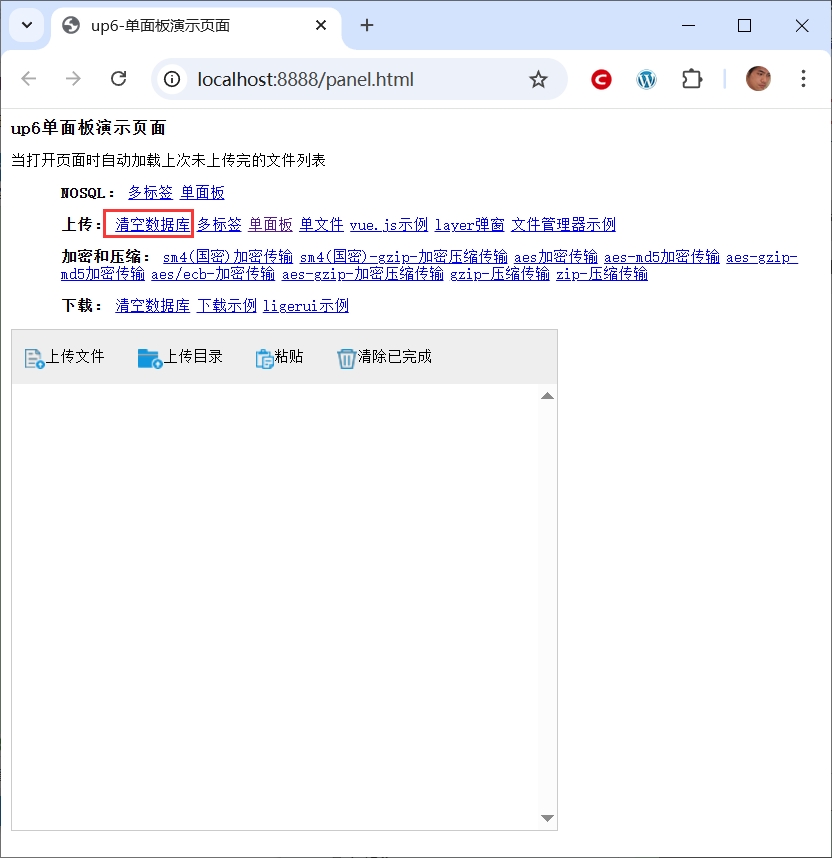
访问页面进行测试
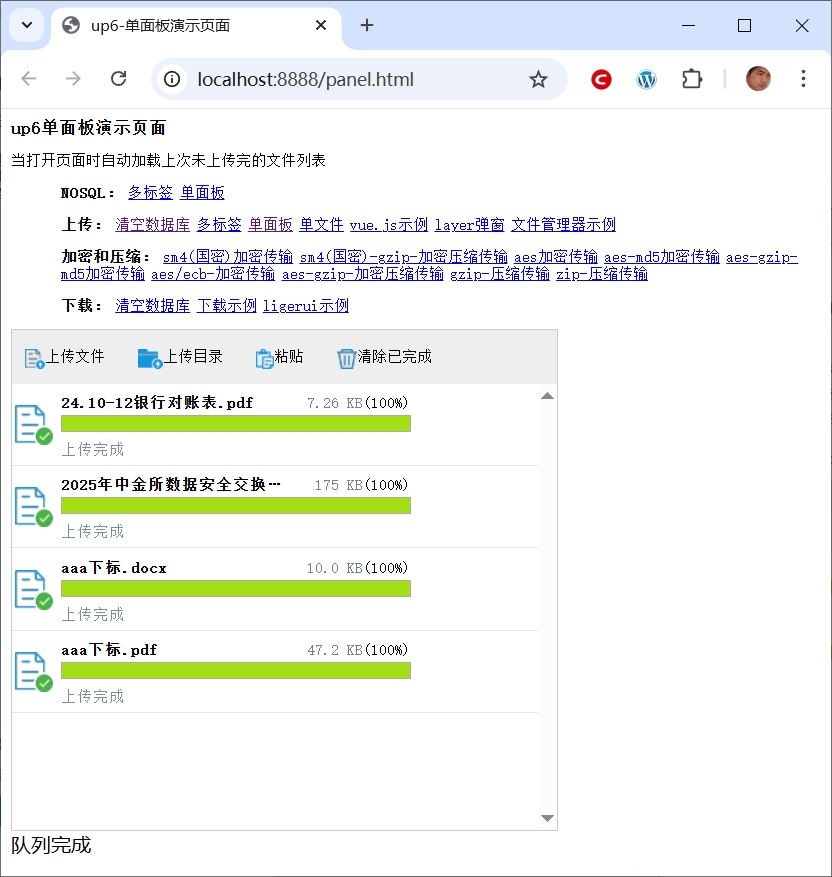
检查数据库数据

检查上传的文件

相关参考:
免费下载产品源代码-泽优全平台开源大文件传输解决方案(up6-down2)
源码工程文档:https://drive.weixin.qq.com/s?k=ACoAYgezAAw1dWofra
免费下载源代码:https://drive.weixin.qq.com/s?k=ACoAYgezAAwbdKCskc
免费下载授权器:https://drive.weixin.qq.com/s?k=ACoAYgezAAw0P06owX