jsp下载文件夹的解决方案
需求:
文件批量下载,支持断点续传。支持多线程下载。
使用JS能够实现批量下载,能够提供接口从指定url中下载文件并保存在本地指定路径中。
服务器不需要打包。客户要求不打包下载,而是直接批量下载。因为文件比较多,打包下载比较麻烦,下载下来后也需要手动解压。
能够下载到本地指定目录,而不是浏览器默认的下载目录。
支持大文件断点下载。比如下载10G的文件。
PC端全平台支持。Windows,macOS,Linux
全浏览器支持。ie6,ie7,ie8,ie9,ie10,ie11,edge,firefox,chrome,safari
压缩文件代码工具类:
public class UrlFilesToZip {
private static final Logger logger = LoggerFactory.getLogger(UrlFilesToZip.class);
//根据文件链接把文件下载下来并且转成字节码
public byte[] getImageFromURL(String urlPath) {
byte[] data = null;
InputStream is = null;
HttpURLConnection conn = null;
try {
URL url = new URL(urlPath);
conn = (HttpURLConnection) url.openConnection();
conn.setDoInput(true);
// conn.setDoOutput(true);
conn.setRequestMethod(“GET”);
conn.setConnectTimeout(6000);
is = conn.getInputStream();
if (conn.getResponseCode() == 200) {
data = readInputStream(is);
} else {
data = null;
}
} catch(MalformedURLException e) {
logger.error(“MalformedURLException”, e);
} catch(IOException e) {
logger.error(“IOException”, e);
} finally {
try {
if (is != null) {
is.close();
}
} catch(IOException e) {
logger.error(“IOException”, e);
}
conn.disconnect();
}
return data;
}
public byte[] readInputStream(InputStream is) {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length = -1;
try {
while ((length = is.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
baos.flush();
} catch(IOException e) {
logger.error(“IOException”, e);
}
byte[] data = baos.toByteArray();
try {
is.close();
baos.close();
} catch(IOException e) {
logger.error(“IOException”, e);
}
return data;
}
}
控制层代码:
public void filesdown(HttpServletResponse response) {
try {
String filename = new String(“xx.zip”.getBytes(“UTF-8”), “ISO8859-1”); //控制文件名编码
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ZipOutputStream zos = new ZipOutputStream(bos);
UrlFilesToZip s = new UrlFilesToZip();
int idx = 1;
for (String oneFile: urls) {
zos.putNextEntry(new ZipEntry(“profile” + idx); byte[] bytes = s.getImageFromURL(oneFile); zos.write(bytes, 0, bytes.length); zos.closeEntry(); idx++;
}
zos.close();
response.setContentType(“application/force-download”); // 设置强制下载不打开
response.addHeader(“Content-Disposition”, “attachment;fileName=” + filename); // 设置文件名
OutputStream os = response.getOutputStream();
os.write(bos.toByteArray());
os.close();
} catch(FileNotFoundException ex) {
logger.error(“FileNotFoundException”, ex);
} catch(Exception ex) {
logger.error(“Exception”, ex);
}
}
注意:
String filename = new String(“xx.zip”.getBytes(“UTF-8”), “ISO8859-1”);//包装zip文件名不发生乱码。
2.一定要注意,否则会发生下载下来的压缩包无法解压。在给OutputStream 传值之前,一定要先把ZipOutputStream的流给关闭了!
效果:
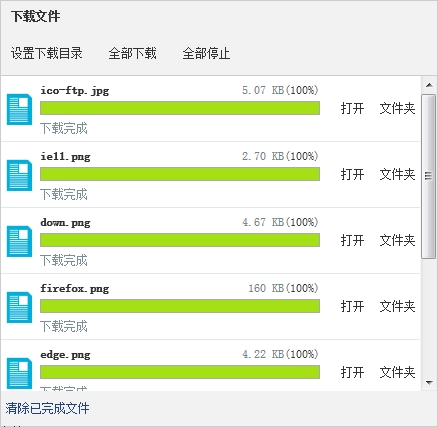
总结
以上所述是小编给大家介绍的JAVA 根据Url把多文件打包成ZIP下载,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。
详细配置信息可以参考我写的这篇文章:http://blog.ncmem.com/wordpress/2019/08/28/java%e6%89%b9%e9%87%8f%e4%b8%8b%e8%bd%bd/